开源Grok,不只是对OpenAI的“回击”,马斯克还有更大的谋划
每经记者 文巧 每经编辑 兰素英
3 月 18 日,马斯克旗下大模型公司 xAI 兑现诺言,正式对 Grok-1 大模型开源。随后在 X 平台上,马斯克还不忘嘲讽 OpenAI 一番," 我们想了解更多 OpenAI 的开放部分 "。
据悉,Grok-1 模型参数大小为 3140 亿,是迄今为止业界开源参数最大的模型。
马斯克的开源举措引发了业界的广泛关注和热烈讨论。表面上,这一举动像是针对 OpenAI 的一记 " 回击 ", 但从更深的层次来看 , 还隐藏着马斯克的战略谋划和考量。
据 xAI 去年公布的文档,尽管 Grok-1 在各个测试集中呈现的效果要比 GPT-3.5、Llama2 要好,但距离 Palm-2、Claude2 和 GPT-4 仍然差了一大截。
因此有分析认为,在强敌环伺,且 Grok 难以匹敌顶尖大模型的情况下,马斯克选择开源是必然之举,其考量之一可能是将模型迭代进化的任务交给社区。
开源还是闭源,一直是 AI 浪潮之下一个极具争议性的话题。有 AI 专家此前在接受《每日经济新闻》记者采访时认为,开源已是大势所趋。从商业角度来看,开源不仅能够避免少数财力雄厚的科技公司控制前沿模型,对于 AI 创业者来说,也进一步降低了门槛和成本。
马斯克的 " 阳谋 ":让开源社区迭代模型
3 月 18 日凌晨,马斯克旗下大模型公司 xAI 宣布正式开源 3140 亿参数的混合专家(MoE)模型 Grok-1 以及该模型的权重和网络架构。截至发稿,在 Github 上,该开源项目已经揽获 31.6k 星标,足见其火爆程度。
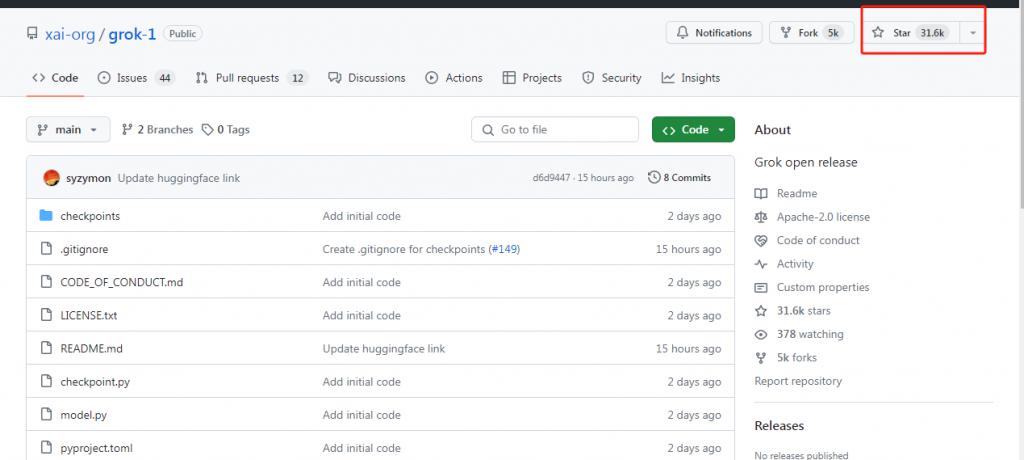
图片来源:Github
值得注意的是,这是迄今为止业界开源参数最大的模型,超过 GPT-3.5 当时 1750 亿的参数量。
DeepMind 工程师 Aleksa Gordié 预测,Grok-1 的能力应该比 Llama2 要强,但目前尚不清楚有多少数据受到了污染,二者的参数量也不是一个量级。
从 Grok-1 的模型细节来看,值得注意的一点是,该基础模型基于大量文本数据进行训练,没有针对任何具体任务进行微调。而在 X 平台上可用的 Grok 大模型就是微调过的版本,其行为和原始权重版本并不相同。也就是说,xAI 目前开源的 Grok-1 模型并不包括 X 平台上的语料。
据 xAI 去年公布的文档,从 Grok-1 的整体测试效果来看,Grok-1 在各个测试集中呈现的效果要比 GPT-3.5、70 亿参数的 Llama2 和 Inflection-1 要好,但距离 Palm-2、Claude2 和 GPT-4 仍然差了一大截。

图片来源:xAI
基于此,有分析认为,马斯克开源 Grok-1 的一个考量是,尽管该模型表现尚可,但 " 比上不足,比下有余 ",并未具备打败顶尖模型如 GPT-4 的能力,更别说未来的 GPT-5。
在大模型角逐的当下,尽管 Grok 依托 X 平台的数据,但其无论是在能力上,还是知名度上都不具备与 OpenAI、谷歌、Anthropic 等公司匹敌的优势。尤其是今年以来,谷歌发布了 Gemini,Anthropic 发布了 Claude3,大型语言模型的竞争更加激烈,在这样的情况下,马斯克选择开源路线也是必然之举。
模型开源让研究者和开发者可以自由地使用、修改和分发模型,打开了更多开放合作和创新的可能性。因此,一次性开源可以将迭代进化的任务交给社区。
正如月之暗面 CEO 杨植麟在此前接受腾讯采访时表示," 如果我今天有一个领先的模型,开源出来,大概率不合理。反而是落后者可能会这么做,或者开源小模型,搅局嘛,反正不开源也没价值。"
再加上马斯克频繁讽刺 OpenAI 并不 Open,外媒 Venture Beat 认为,Grok-1 的开源显然对他来说也是一个有益的立场。
不过,针对让社区来实现迭代这一目的,有业内人士在 X 平台表示,Grok-1 的问题可能是模型参数太大,这需要巨大的计算资源,所以开源社区可能无法对 Grok-1 进行迭代。
另有评论认为,Grok-1 没有对特定任务进行微调,这提高了用户使用它的门槛。AI 工具饱和的市场可能更需要针对特定用例的工具。
开源乃大势所趋,初创公司迎来新机会
开源和闭源是当前 AI 浪潮之下的一个极具争议性的话题。
纽约大学坦登工程学院计算机科学与工程系副教授 Julian Togelius 在此前接受《每日经济新闻》记者采访时曾认为,开源是业界大势所趋,Meta 正在引领这一趋势,其次是 Mistral AI、HuggingFace 等规模较小的公司。谷歌今年 2 月罕见地改变了去年坚持的大模型闭源策略,推出了 " 开源 " 大模型 Gemma,似乎也是对 Togelius 言论的验证。
从技术视角来看,开源代码可以提高透明度并有助于推进技术发展,也能帮助了解模型弱点,这样才能更好地部署模型,从而降低风险。另一方面,也有不少反对开源的一派认为,开源 AI 会被不良行为者操纵从而造成风险。
从商业角度来看,Julian Togelius 认为开源对防止权力集中很重要,能够避免少数财力雄厚的科技公司控制前沿模型。此外,还有分析认为,对于创业者来说,开源大模型则进一步降低了创业门槛,降低了大模型的开发成本,让更多创业者在基础模型方面处于同一起跑线上。
例如,目前许多开源模型都是基于 Meta 的开源模型 Llama2 而开发。据报道,截至 2023 年底,HuggingFace 上开源的大模型排行榜前十名中,有 8 个是基于 Llama2 打造的,使用 Llama2 的开源大模型已经超过 1500 个。
Grok-1 的权重和架构是在宽松的 Apache 2.0 许可下发布的,这使得研究者和开发者可以自由地使用、修改和分发模型,这种开源方式可以适应多种不同的任务和应用场景,更适合那些想要用开源模型打造自己专有模型的开发者。因此,有分析认为,Grok-1 的开源也是为许多 AI 初创公司提供了另一个选择。
例如,AI 初创公司 Abacus AI 的 CEO 就在 X 平台上表示,将开始研究 Grok-1,并在几周内进行更新 / 发布。

图片来源:X 平台
对话搜索引擎公司 Perplexity CEO Aravind Srinivas 也在 X 平台上发文称,将会基于 Grok 的基础模型进行对话式搜索和推理的微调。
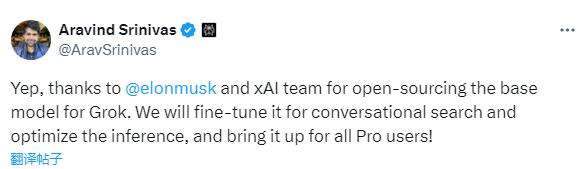
随着开源力量的不断壮大,马萨诸塞大学洛厄尔分校计算机科学教授 Jie Wang 曾对《每日经济新闻》记者表示,未来各个主要参与者可能都倾向于采用半开源的方式,类似 Meta 开源 Llama2 系列大模型的方式,即开源模型的某些部分,以便研究人员和开发人员了解模型的架构和训练过程,但保留最重要的部分,例如用于训练和预训练模型权重的完整数据集。
Grok-1 走的也是这样的路线。
知名机器学习研究者 Sebastian Raschka 认为,"尽管 Grok-1 比其他通常带有使用限制的开放权重模型更加开源,但是它的开源程度不如 Pythia、Bloom 和 OLMo,后者附带训练代码和可复现的数据集。"

















