端到端的自动驾驶,会是一场闹剧么?
实现真正的自动驾驶所面临的最大问题是什么呢?比较常见的一个答案是:我们现在仍然无法穷尽所有的 Corner Case。但是随着 AI 以及大模型技术的发展,将会给人带来希望。" 对自动驾驶系统来说,不论给系统叠加多少条代码和规则,都无法穷尽长尾场景,但 AI 能够理解世界,意味着我们有机会摆脱规则和代码的堆砌,这是令人兴奋的事情。" 某智驾专家解释说。
也就是说,按正常推理,端到端的方案可以把汽车 " 驯化 " 出更高阶的 AI 智能。通过大量有价值数据的训练,逐步提升车端的 " 智力 " 水平,最终使得系统开车的技术水平犹如人类老司机。同样,也有人认为:"OpenAI 的 Chat-GPT 和特斯拉的 FSD V12 端到端都是遵循大算力 + 海量数据的暴力美学,能力来源和机制目前还难以精确地解答。"
从之前的 BEV+Transformer,到后来的占用网络,又到现在的端到端。在智能驾驶算法领域,特斯拉也一直是处于一个引领的地位。但是,端到端大模型训练到什么时候才会出现类似于大语言模型中的 " 涌现 " 现象,都还是未知数。
但基础的 " 本钱 " 在前期是必须要先投进去。这既考验企业的技术预判能力又考验资金实力,不是谁都能押得起。那么,端到端这条技术路线在自动驾驶领域真的靠谱么?国内车企真的有必要继续对标跟进么?
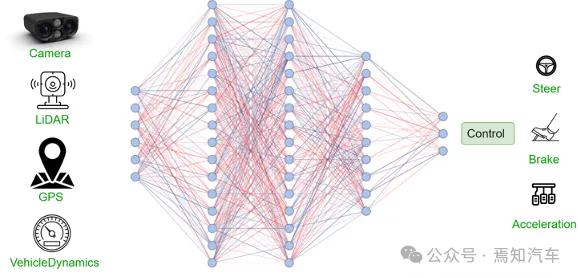
典型的端到端自动驾驶系统示意图
一、什么是端到端的自动驾驶方案 ?
1. 模块化方案
概念定义:将整个驾驶任务进行切分,定义并划分出多个子模块,分别负责不同的任务,这些子模块通常包括地图 / 定位、预测、决策、规划和控制。最后,通过系统集成来完成整个智能驾驶任务。
开发模式:各个子模块可以进行独立的开发和测试,等子模块开发测试完成之后,再进行系统集成,进行系统级的测试和验证。
2. 端到端方案
概念定义:整个智驾系统是一个大的模块,不再进行模块和任务的划分。端到端系统接收到传感器的输入数据后,直接输出驾驶决策(动作或轨迹)。
开发模式:基于数据驱动,整个系统可以作为一个大模型进行梯度下降的训练,通过梯度反向传播可以在模型训练期间对模型从输入到输出之间的全部环节进行参数更新优化。整个系统作为一个大模块进行开发和测试,从表面上看是简化了开发和测试流程。

模块化方案 VS 端到端方案(对比内容:结构、软件形式和开发范式)

模块化方案 VS 端到端方案(对比内容:优缺点)
二、实现端到端所面临的挑战
特斯拉 FSD V12 的量产,被业内看成是自动驾驶发展史上的一个典型转折点,标志着自动驾驶技术真正地从规则驱动阶段过渡到数据驱动阶段。在数据驱动阶段,数据能力将会是车企决胜的关键因素,算法能力和算力资源则是参与竞争的基础。
1. 海量高质量数据的需求
训练端到端自动驾驶系统到底需要多少数据?现在也没有明确的答案,大家都还处于探索阶段。但可以明确的是数据的门槛不仅是对绝对数量的要求,对于数据的分布和多样性要求也极高。毫末智行数据智能科学家贺翔曾对外谈到:" 端到端模型是一个纯粹的数据系统,原则上模型参数够大,数据分布性更好,模型性能就能不断地提高——天花板很高,但烧钱,且费时间。"
同样,2023 年 6 月,一位特斯拉软件工程师在 CVPR 会议的演讲中也谈到了类似的观点;" 对于训练自动驾驶的基础模型,不求无上限的数据量,但求一定量级基础上的‘多样性’。"
另外,在特斯拉 2023 年的一次财报会议上,对于端到端的自动驾驶,马斯克表示:" 我们训练了 100 万个视频片段(clips),勉强可以工作;200 万个 clips,稍好一些;300 万个 clips,就会感到惊喜;训练到 1000 万个 clips,系统的表现就变得难以置信了。" 特斯拉 Autopilot 回传数据的 1 个 Clips 普遍被认为是 1min 的片段,那么入门级别的 100 万个视频 clips 大概就是 16000 小时。
最近几年,随着越来越多配备智能驾驶功能车辆的规模化落地,国内很多车企也都开始基于量产车通过影子模式采集数据。但如何高效获取有价值数据,依然存在一些挑战。

获取高质量数据方面存在的挑战(信息来源:基于公开资料整理)
2. 超大算力的基础设施支持
在 2024 年第一季度财报会议上,特斯拉对外透露,其已将训练 AI 集群扩展到 35000 块 H100 GPU。按照计划,到 2024 年底,特斯拉将会在超算集群上再投入 15 亿美元(包括 Dojo 的 5 亿美元、英伟达 H100 的 5 亿 + 美元,以及未知金额的 AMD 芯片),目标是将其超算中心的总算力提升到 100EFLOPS。
如果用不太严谨的方法简单做个估量:可以理解成,假设某家车企在数据和算法水平上跟特斯拉处于持平的状态下,想要把端到端的模型训练到 FSD V12 当前的水平,GPU 训练卡的需求也得至少要达到特斯拉目前的算力规模,即 35000 块英伟达 H100 相当的水平。有消息人士爆料,目前一块 H100 GPU 卡官方售价为 3.5 万美元,在黑市甚至被炒到 30-40 万元人民币。按官方售价计算,35000 块 H100 芯片需要花费 12.25 亿美元。
受美国对我国芯片制裁的影响,国内企业采购英伟达 H100 GPU 已经是难上加难。甚至现在连阉割版的 A800/H800 都已经被禁止向中国市场销售了。据了解,国内能拥有 1000 张以上 H100 的企业都寥寥无几。因此,如何在算力受限的情况下,去走通这种 " 大力出奇迹 " 的端到端的技术路线,是值得深思的问题。
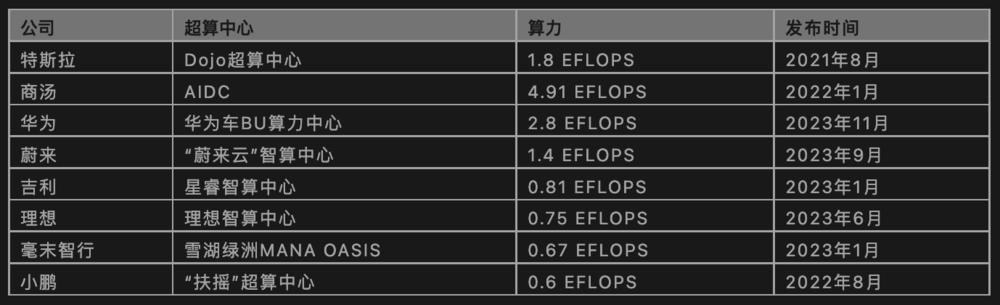
主流车企及自动驾驶厂商超算中心布局情况(信息来源:基于公开信息整理)
3. 端到端大模型的训练问题
设计并训练出一个 " 可用 " 的端到端神经网络模型,也是一件十分有挑战的事情。
" 设计一个可工作的推理神经网络需要大量的专业知识,而训练它就更复杂。例如,需要选择合适的输入 / 输出信号、归一化、偏差、神经网络层数、每层神经元数量、非线性输出函数(例如 RELU)…… 并且整个系统中的许多神经子网络都可能涉及这些问题,工作量巨大。" 一位人工智能专家谈到。
据相关专家的调研分析,即便是特斯拉的 FSD V12,它的端到端的神经网络模型也是建立在前序版本基础之上,是在原有技术基础上一步步去掉部分的规则代码,并逐渐实现端到端可导。特斯拉通过之前搭载 FSD V9、FSD V10、FSD V11 的大量车型,收集大量真实数据,从而训练出了处理各分任务的模型,在研发迭代过程再不断将这些中小任务模型进行聚合和重组,并最终形成 FSD V12 的模型方案,这是一个循序渐进的过程,万丈高楼平地起,而不是空中楼阁。
4. 组织架构的适配性问题
实现端到端,算力、数据和算法是关键的三要素,缺一不可。除此之外,智能驾驶团队的组织架构也需要随着技术路线的改变而进行适配性的调整。
如果车企采用端到端的方案,那么,对于现在自动驾驶研发团队的组织架构而言,不同模块项目组在开发协作上也存在比较大的挑战。目前车企的自动驾驶研发团队架构,基本上还是按任务模块划分成不同的项目组或工作组。然而,端到端的技术方案直接消除了不同模块间的接口壁垒,开发模式也将会产生比较大的变化。从开发效率上来说,组织架构和开发范式相匹配才是最优选择。因此,车企需要重新规划和调整整个研发团队的人力资源以适配新的技术开发范式。
另外,组织架构的变动,必然也会涉及到人才需求的变化。某业内人士谈到:" 即便到了端到端的阶段,虽然对组织架构有些影响,但是独立的预测和规控小组应该还是有必要存在的,需要用来为安全兜底。但是这方面的人才需求变小也是必然趋势。与之相对应,懂车并且懂深度学习方面的人才将会变成强需求。"
针对人才需求的话题,另外一位智驾从业者的预判是:" 在未来,虽然端到端的技术方案,将会减少大量的人工编码工作。但仍需人类工程师手写代码来完成筛选数据、处理数据、组织模型训练等工作。这些代码少而精,需要基础扎实、经验丰富的工程师团队反复试错、验证。然而,这样的人才在国内却是少之又少。"
三、" 端到端 " 自动驾驶离我们还远么?
关于端到端的方案,大家的看法不一,但整体上感觉还是比较理性的,认为实现真正的端到端可能还需较长一段时间的路要走。下面分享几个我关注到的比较有代表性的观点:
A 观点:
" 端到端大模型过于神化了,一个统计模型而已,距离人的思维认知能力还差得远,稳定性完全不能保障。把人命压在这个上面就有些太不负责任了。"
B观点:
" 端到端最大的问题在于:它还是基于过往的数据训练出来的模型,若有劣质数据进入云端,必然导致训练出来的模型有各种瑕疵。如果通过手工排除劣质数据,恐怕是另外一个不能承受之痛。端到端模型的智能化程度还是严重依赖训练数据的质量和数量。马斯克经常谈第一性原理,拿摄像头跟人的眼睛做对比。但人眼的分辨率要比当前车载摄像头高很多,并且人脑的分析推理能力以及脑补能力也是目前 AI 所无法比拟的。总之,理想很丰满,现实很骨感,思路很好,但道阻且长。"
C 观点:
" 端到端不仅是烧钱巨坑,还是个长期工程,很多企业在短期内很难看到结果。这也意味着,端到端是少数企业的游戏,只有资金储备充足、且愿意长期投资的头部公司,才有能力支持端到端所需的庞大数据与算力。"
其实,到底需要多大的算力基础设施资源,需要多大规模以及什么样的数据量,才能把端到端模型训练到可用,甚至达到 " 涌现 " 的状态,以及端到端大模型训练好之后如何在车上部署,都是现在亟需思考的问题。如果这些关键问题都还没有考虑清楚,就直接开始鼓吹要实现端到端量产上车,最后很可能会落得个 " 邯郸学步 " 的结果。