谷歌Meta离职团队4个月训出比肩GPT-4大模型,清华北航校友参与
文|李然
编辑|苏建勋
大模型牌桌上又多一名高端玩家。

图源:X
试用链接:https://chat.reka.ai/auth/login
由前 DeepMind, Google Brain, FAIR 出走的大佬共同创立的 Reka AI,发布了它们最新的多模态大模型 Reka Core,各项能力全面比肩 GPT-4!

图源:官网
在几项最重要的测试集上,它的能力和 GPT-4,Gemini Ultra 打得有来有回。
而且它能支持 3 种模态数据的混合输入,目前在主流大模型产品中能做到的只有 Gemini,而且它的多模态性能甚至比 Gemini Ultra 还要略强。
具体来说,Reka Core 的主要技术亮点体现在这几个方面:
多模态能力:具备图像,视频和音频理解能力。它对图像、视频和音频具有强大的上下文理解能力,是目前市面上除了 Gemini 之外唯二的全模态能力模型。
128K 上下文窗口。
极强的推理能力。
Reka Core 具有超强的推理能力(包括语言和数学),因此适合执行需要复杂分析的任务。
而除了超大杯 Reka Core 之外,团队之前就已经放出了两个小型的开源模型 Reka Flash 和 Reka Edge。
最令人咂舌的是,这个模型性能完全对标 GPT-4 的产品诞生于一个只有 22 人的团队——
成员几乎都是远程办公,接近半数亚裔,分布在包括加州、西雅图、伦敦、苏黎世、香港和新加坡等地。

用他们自己的说法,这只 " 小而凶猛 " 的团队在过去十年中为人工智能领域的许多突破做出了非常大贡献。

图源:领英
根据 CTO 的介绍,这个模型是 20 人的团队在最近 4 个月内才肝出来的,因为他们 90% 的算力在去年 12 月底才到位。
随着 Reka Core 的发布,他们从幕后走到舞台中央,让 " 大模型 " 第一次进入 " 小团队 " 时代!
能看懂三体的大模型
在官方的演示中,Reka Core 对网飞《三体》第一集那个经典场景进行了解读:

来源:官方素材
视频中一个人在昏暗的房间里,将手电筒照在墙上。墙上有很多用红色和黑色墨水写的数字和等式。这个人似乎在很认真地研究这些数字,然后转过身来对着镜头开始说话,提到了倒计时和一系列杀人案件似乎有某种关系。
如果让一个没有看过《三体》的人来看这段视频,能不能这么全面地捕捉到这些细节都很难说。而且 Reka Core 很自然地理解并且整合了视频中场景的切换,人物动作的意图,以及声音等多模态的信息。

紧跟着再把后边一段和 " 倒计时 " 有关的视频喂给它,它不但清楚地理解了视频中的信息,而且还将这个片段画面中的倒计时和上一个视频中声音信息中的倒计时主动联系了起来。
视频中的倒计时让人感到了不安和一种迫近的危险。这可能和那个男人提到的一连串的谋杀案有关。这可能和一个定时炸弹或者某个截止时间有关。人物可能要在这个截止时间之前来做什么事情,从而避免灾难性结果的发生,或者解决一个什么谜题。当然,这个倒计时也可能代表了时间的有限性,人物在混乱的环境中不得不面对的挣扎。
除了多模态素材理解能力超强,Reka 的代码能力也非常彪悍。
官方演示了一段 Reka Core 输出的可视化 " 三体问题 " 的 python 代码:

它还能准确地识别出《三体》中的演员。Reka Core 把他在其他作品中饰演的人物都自动联想出来。

镜头中直升机的具体型号,大型粒子对撞机的位置,都推断得有理有据。

技术细节
Reka Core 是一个闭源模型,但是 Reka 之前已经开源了两个较小的模型 Reka Flash(21B)和 Reka Edge(7B)

技术报告:https://publications.reka.ai/reka-core-tech-report.pdf
训练数据
根据官方公布的对于训练数据的说明,Reka 三个模型训练数据包括公开数据集和专有 / 授权数据集,数据集的知识截止日期为知识截止日期为 2023 年 11 月。
模型所摄取的数据集包括文本、图像、视频和音频片段。两个体量较小的开源模型 Reka Flash 和 Reka Edge 分别在大约 5 万亿和 4.5 万亿 token 的数据上进行了训练。
预训练数据中约有 25% 与代码相关,30% 与 STEM 相关。大约 25% 的数据是从网络抓取的。
模型结构

图源:技术报告
模型的整体架构如上图所示,是一个模块化的编码器 - 解码器架构。支持文本、图像、视频和音频输入,不过目前仅支持文本输出。
骨干 Transformer 基于 "Noam" 架构。从架构上看,与 PaLM 架构相似,但没有并行层。
数据集表现
根据官方给出的数据集表现,Reka Core 已经完全不输 GPT-4,而小一些的开源模型 Reka Flash 的多模态能力也和 Gemini Pro 1.5 差不多了。

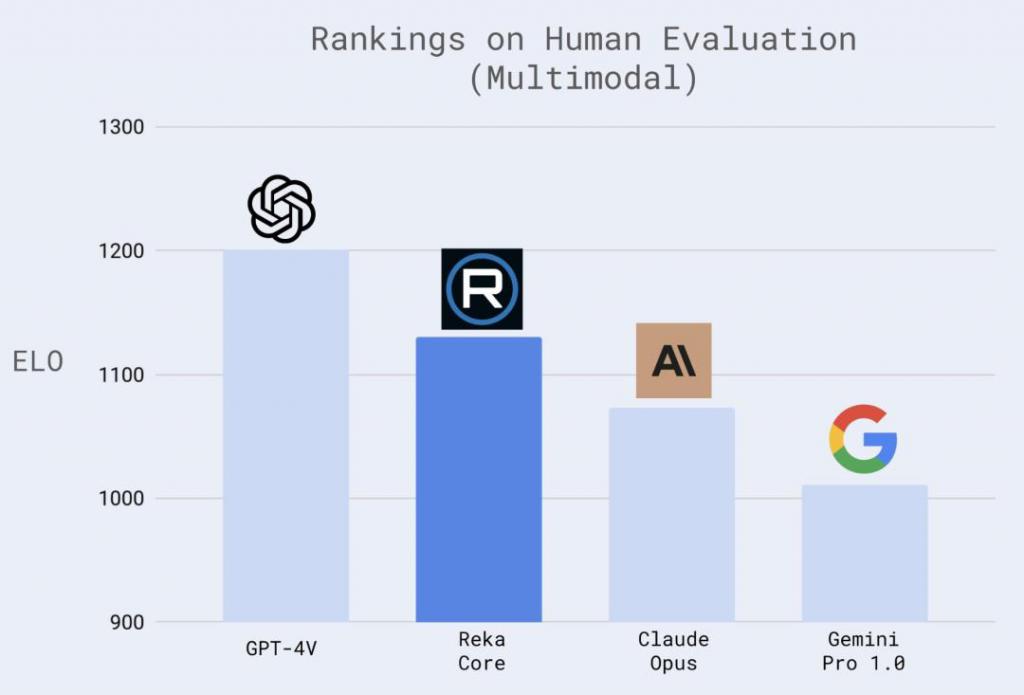
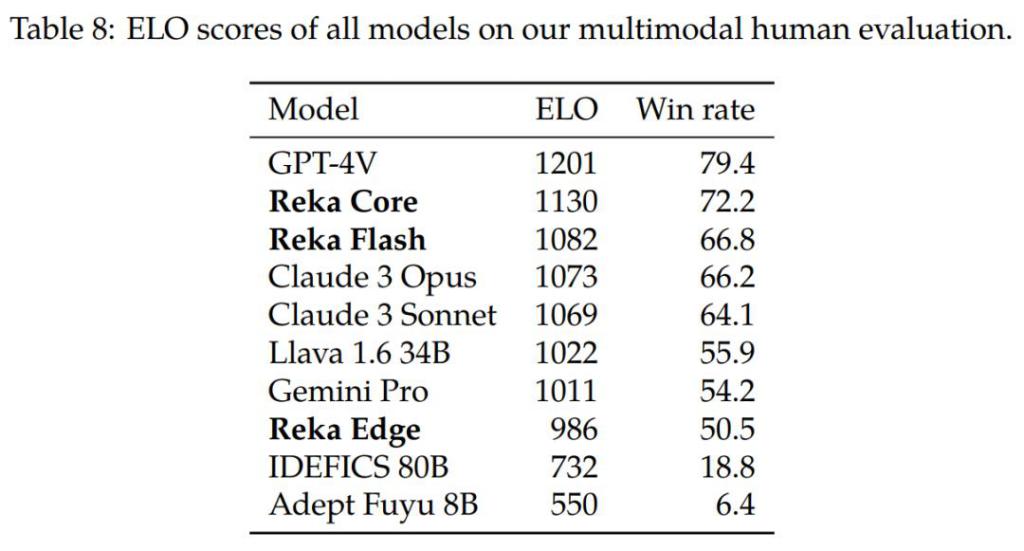
在人类测试者参与的对于市面上几个主流模型的打分反馈结果来看,Reka Core 的多模态测试成绩超过了 Claude 3 超大杯,落后 GPT-4V 不多。
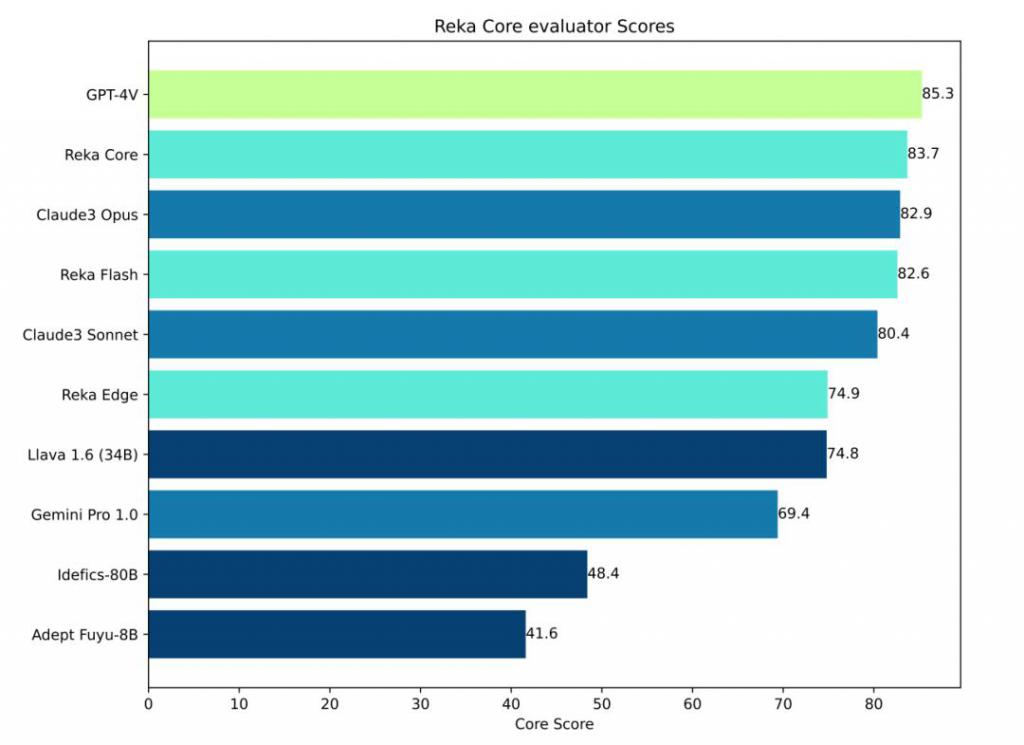
在这个测试之后,Reka 团队还让 Reka Core 自己扮演人类评分者的角色,对于每个模型的输出进行了打分评估,得到的结果也和人类评分结果非常接近。
同样在人类测试者参与的纯文本的测试中,Reka Core 的成绩也仅次于 GPT-4 Turbo 和 Claude 3 超大杯。

团队成员介绍
CEO/ 联合创始人 Dani Yogatama

他出生于印尼,2015 年博士毕业于 CMU。曾经短暂就职于百度硅谷 AI 实验室,之后加入 DeepMind,工作至 2022 年。现在是 Reka AI CEO,同时还是南加大计算机系副教授。
他在创立 Reka AI 之前的研究生涯,参与了多篇知名的论文。
图源:谷歌学术
CTO/ 联合创始人 Yi Tay

他来自新加坡,曾经担任谷歌 Research 的技术主管,谷歌大脑高级研究科学家。在谷歌任职期间,他对许多大模型项目做出了贡献:例如 PaLM、UL2、Flan-{PaLM/UL2/T5}、LaMDA/Bard、MUM 等。

他除了是一个非常成功的深度学习科学家和创业者之外,还是一个业余古典钢琴演奏家,在 2012 年获得了伦敦三一学院古典钢琴演奏副文凭。
联合创始人 Qi Liu

他博士毕业于牛津大学,曾经在 Fair 担任研究员,现在除了是 Reka AI 的联合创始人之外,还在香港大学担任计算机系助理教授。

Che Zheng

他本科毕业于清华大学,硕士毕业于 CMU,在加入 Reka AI 之前曾经在快手和谷歌任职。


Zhongkai Zhu

他在加入 Reka AI 之前曾今在 Meta AI,微软,特斯拉任职,本科毕业于北航。